

The Whole Point Was the Mess
LLMs read unstructured language by design. The GEO/AEO playbook is SEO best practices repackaged as novelty.

Semrush put out an infographic last week. The kind built to be screenshotted into LinkedIn carousels and pasted into webinar decks. Four pillars. The fourth one is called “Technical GEO”: schema, structured data, clean architecture. The line that justifies it: “Ensures AI engines can parse and connect your content.”
Ensures.
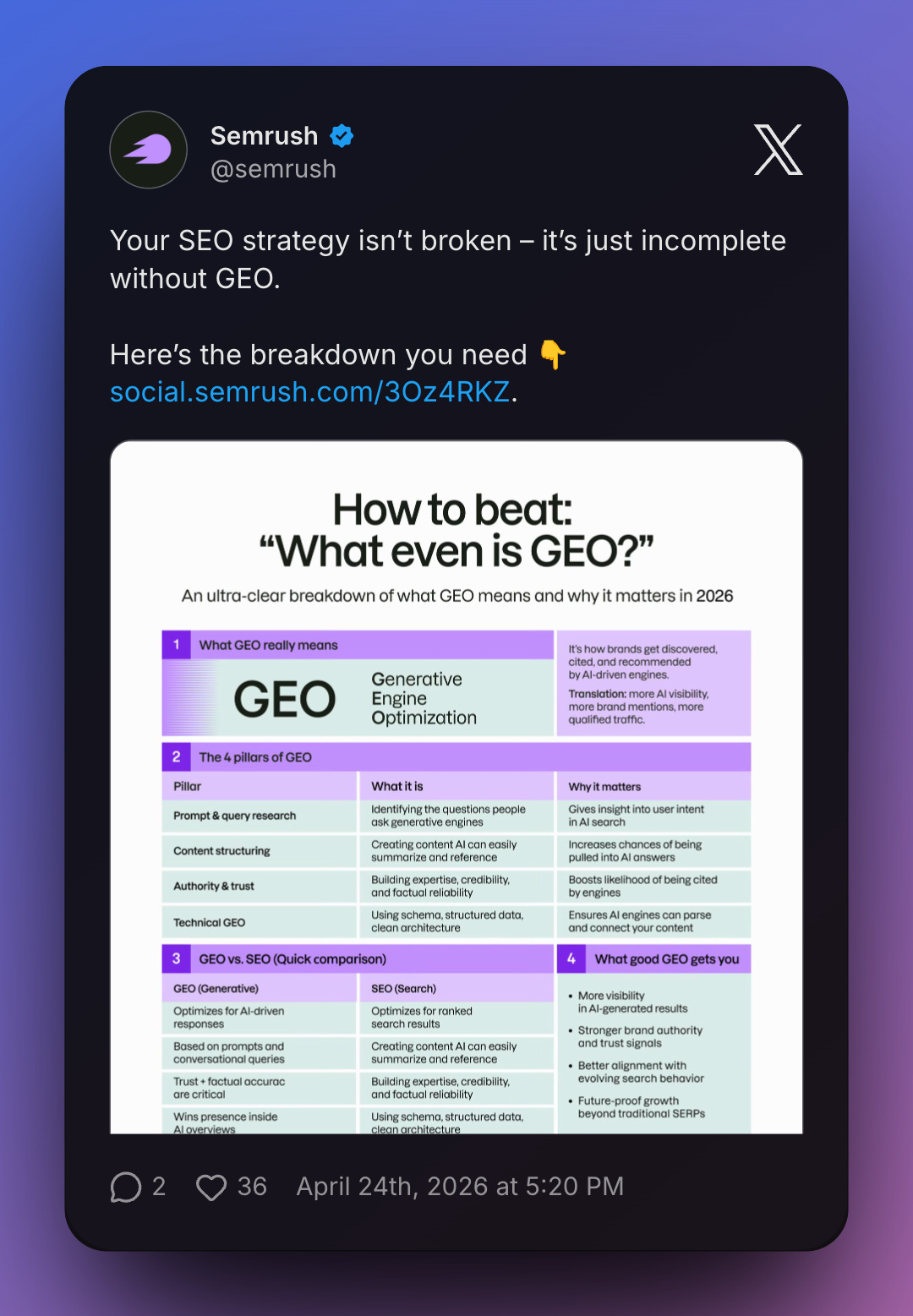
That is the entire piece in one word. The architecture of large language models is, by design, the opposite of ensured. And schema has nothing to do with whether an LLM can parse text. LLMs parse text by reading text.
Semrush is far from alone. Every SaaS vendor with skin in this game is running variations of the same play. SEO-era controllability, repackaged under a new acronym. The same percentages, pillars, and pyramids. All dressed for a system that was built specifically not to work this way.
I have made the strategic version of this case before, in Your AI Strategy Isn’t a Strategy. This piece is the technical floor underneath it.
Built to read whatever’s there
Language models exist because the web is a mess. Forums, Wikipedia stubs, blog posts written at 2am, scraped product copy, machine-translated junk, code comments, half-formed sentences, typos, contradictions, every register from journal article to subreddit shitpost. Pre-training data is the public web, and the public web has never been structured.
The transformer architecture handles this by treating language as sequences of tokens. There is no parser inside the model looking for <schema> tags. There is no preference for FAQ markup. The model reads the words. That is the mechanism.
At inference time, the model generates more tokens conditioned on the input. None of that pipeline is reading microdata.
Schema.org has real jobs. It feeds rich results in classical search. It supports entity disambiguation in the Knowledge Graph. It helps voice assistants pull structured fields. These are well-defined functions inside specific systems. They are not the mechanism by which an LLM understands a sentence.
So when a vendor claims structured data “ensures AI engines can parse and connect your content,” there is nothing to ensure. The parsing layer they are imagining is not there. The model already parsed your sentence. It did so by reading the sentence.
One trick, three brand colours
Look at the biggest GEO and AEO explainers in market right now and you find the same SEO-era playbook with the acronym swapped.
Semrush is already covered. The fourth pillar of their “Technical GEO” presents schema and structured data as ensuring something that the architecture cannot ensure.
AirOps published a graphic titled “15 Ways to Get Cited by ChatGPT, Perplexity, & Google.” It is the most numbers-heavy specimen of the genre I have seen this year. Schema markup increases citation likelihood by 13 percent. Sequential H2 to H4 tags double your chances. Short paragraphs make content 49 percent more likely to appear in AI answers. Perplexity cites UGC in 91 percent of answers, versus Gemini’s 7. Read the source notes and the methodology trail comes home. The numbers in the graphic trace back to AirOps’s own 2026 State of AI Search Report. AirOps is citing AirOps on the question of whether AirOps’s prescriptions work.
Peec AI does a more honest job in places. Its complete guide to GEO acknowledges the probabilistic nature of the system and concedes that foundation models are already trained, so optimisation focuses on the retrieval layer. Then it lands the same prescriptions: heading hierarchy, bullet lists, FAQ markup, multiple schema types layered on each page, summaries at the top of sections — all built on the chunking claim that long paragraphs lose out because the engine extracts fragments rather than full articles.
Profound, citing Aleyda Solis’s checklist, is the most explicit in their piece: “Optimize for Chunk-Level Retrieval.” Each section, a standalone snippet. Each page, a buffet from which the engine takes what it wants. The engine, in this telling, is a polite guest who only takes what’s been laid out.
Three vendors. Same operating assumption: a controllable, prescriptive technical discipline sits between a publisher and a citation, and it occupies roughly the same shape as classical SEO. Schema, headings, structure, freshness, machine-readable formats. Familiar. Billable. Reportable up to a CMO.
What schema actually does
Schema is not the target here. Schema has real, well-defined uses. Classical Google search uses it for rich results: prices, ratings, event times, the structured fields that drive SERP features. The Knowledge Graph uses it for entity disambiguation. Voice assistants pull structured fields out of it.
None of that goes away. If you’re responsible for technical SEO, keep implementing schema where it earns its keep.
Schema cannot reach into a transformer and improve its comprehension of your prose. The model isn’t architected to read schema as schema. It receives whatever text the engine fetched and chose to include, and processes that text as language tokens. The entire GEO/AEO marketing layer rests on conflating two distinct claims: that schema is useful in classical search, and that schema feeds the LLM. The first is true. The second is a category error.
Chunking is not yours to optimise

The chunking advice keeps reappearing because it sounds technical, sits neatly inside a flowchart, and gives a content team something concrete to do on Monday morning. It is also incoherent.
Chunking happens at retrieval time. Perplexity, ChatGPT, and Gemini each run a retriever over candidate documents, split them according to their own configurations (length, overlap, embedding model, sometimes semantic boundaries), and feed the top-k chunks into the model’s context. Those configurations belong to the engine. They get tuned differently across systems and retuned on schedules no publisher is privy to. The publisher’s view of the chunker is the publisher’s view of the model: black box, results only.
So when a vendor says “optimise for chunk-level retrieval,” what is actually being recommended is good writing. Short, self-contained paragraphs. Clear definitions near the top of sections. Internal logical structure. These are recognisable disciplines: information architecture, technical writing, readability. They have been recognisable disciplines since long before the transformer was invented. They are not a new technical layer.
A more honest version of the pitch would be: hire someone competent at writing for the web. That sentence does not fit on a pricing page.
The paper they don’t read
There is an actual academic paper called “GEO.” Aggarwal and co-authors, KDD 2024. It is the closest thing to a citable source the SaaS layer has when it sells Generative Engine Optimization as a discipline. It is also, as papers go, easy to skim. Nine “optimisation methods” are tested on a 10,000-query benchmark, with results.
What did the paper find worked?
Adding citations from credible sources. Adding quotations from relevant sources. Adding statistics. Improving fluency. Making prose easier to understand. The methods that produced the largest visibility lifts were essentially: write content with more evidence in cleaner prose.
What did the paper test and find did not work?
Keyword stuffing, the closest analogue in the paper to the SEO-era playbook the current GEO and AEO vendors have repackaged. Result: below baseline. The paper’s authors note in plain terms that techniques effective in search engines “may not translate to success in this new paradigm.”
Notice what is not in the list of nine methods. Schema. Structured data. FAQ markup. Heading hierarchy. Machine-readable formats. None of these are tested in the paper, because none of them are the optimisation surface the paper studies. The paper is studying content-level interventions: what you put in the words, not metadata layered around the words.
The SaaS layer borrowed the acronym. The findings stayed in the paper. “Technical GEO” is the SEO playbook with different stickers on the same boxes, sold against research that points the other way.
The assumption smuggled in
The SaaS pitch only makes sense if you smuggle in one assumption: that the system you’re optimising for has the same shape as the one that’s been billing SEO clients for a quarter-century. Inputs you control. Outputs that respond. A retrievable causal chain between the two.
That model was always a simplification of how search worked. It was close enough to keep the industry running, and close enough to keep the invoices going out.
None of that simplification survives contact with generative systems. The same prompt produces different answers across sessions, users, temperatures, model versions, and days. Observed behaviour across the major engines, not a clean property of any single one. The retrieval layer in front of the model also moves: candidate sources shift, ranking shifts, freshness windows shift. No causal chain runs between “I added FAQ schema” and “the model cited my page.” What runs between them is a probability distribution, and the things you control affect that distribution in ways nobody can cleanly attribute. Not even the people who created these systems.
This is the established line on AI visibility tools, repeated here because it applies to the whole prescriptive layer. Statistically unverifiable data drawn from non-deterministic systems. A 13 percent citation lift, measured how, against what counterfactual, with what reproducibility? The methodological questions aren’t what those numbers are designed to answer. The numbers are the answer. They land in a graphic, get rendered as ROI in a board deck, and the conversation moves on.
Something to say in the meeting
Here is the part that the architecture argument and the methodology argument do not, on their own, explain. Why does the entire SaaS layer keep successfully selling this stuff to people who are not stupid?
The honest version of the answer goes something like: we are operating with reduced visibility into a system that does not expose its mechanics, that returns different outputs to different people for the same query, that is changing month by month, and that has folded a substantial chunk of the funnel into a black box. We can keep doing the work that has always been the work: writing well, being useful, building authority, maintaining the site. We can monitor what shows up where. The deterministic dashboard we used to have is not coming back.
That sentence is unsayable in a marketing meeting. It admits the lever is not connected. It tells leadership that the budget line they approved does not have a corresponding action. It gives the team nothing to put in next quarter’s plan.
So the SaaS layer fills the gap. It manufactures levers. Pillars, frameworks, percentage lifts, schema audits, chunking optimisation, machine-readable formats. Reportable activity. Defensible expenditure. Something to say in the meeting. None of this gets you visibility. The engine decides that. What is on offer is the appearance of control, sold to people who would rather pay than concede that control left the room.
Once the lever is bought, it has to be operated. Schema audits get scheduled. Chunking checklists get reviewed. Citation likelihoods get tracked, refreshed, and compared. The dashboard the team paid for becomes the dashboard the team optimises against, and the dashboard quietly replaces the actual problem with the part of the problem it can see. By the time anyone notices, the SaaS layer is writing the brief.
None of this is a moral failure on the buyer’s side. What you are watching is what happens when an industry has been organised for a quarter-century around the premise that you can pull a lever and watch the meter move, and the meter quietly disconnects from the lever. The vendors aren’t running a con. They are filling demand for the only thing the buyer can no longer afford to do without: an answer that fits in a slide.
Rank and tank, all over again
I keep coming back to a phrase that fits this whole moment: dancing to the rank-and-tank tunes (I borrowed it from David McSweeney). The cycle goes: vendor sells the controllable-discipline frame, agencies adopt it, content teams scale production around the prescriptions, AI-generated articles get pumped out at volume because the prescriptions are easy to template. Some of it ranks for a while. Most of it eventually tanks because the prescriptions were never the mechanism, and the engine adjusts, or the freshness window closes, or the system simply moves on.
The SEO industry has done this before. Spinning. Mass programmatic pages. Doorway content. Each cycle followed the same shape: a controllable input dressed as a discipline, sold at scale, briefly effective, eventually punished by the engine, replaced by the next controllable input dressed as a discipline.
GEO and AEO are the current cycle. The pillars and percentages and pyramids are this cycle’s templates. Underneath them, the strategies bifurcate.
One path is brand presence exploitation. Plant your name where the engines look. Reddit threads, top-X listicles, the same citation surfaces over and over. The cycle feeds itself: engines cite the surfaces, brands work the surfaces, surfaces feed the engines. I have written about this loop before; I called it the Ouroboros pattern. The short version is that the loop is less stable than the strategy assumes.
The other path is content at scale. Produce variations, pump out volume, treat the templated output as content that could earn a citation. I have written about this approach before, in the Scaling Disappointment piece. The short version is that uniqueness is not value, and at the pace these prescriptions enable, qualitative review stops being possible. The volume of AI-generated copy produced under this path is this cycle’s externality.
The next cycle will sell the cleanup.
Forget for a second whether your “Technical GEO” is set up correctly. Ask whether the thing you are putting on the page is worth reading. Large language models were designed to read whatever is there. If what is there is good, it will be read. If what is there is templated, low-utility content optimised against a chunking heuristic that does not exist, it will eventually be filtered out: by the engine, by the user, or by the next academic paper showing that retrieval quality is degraded by exactly this kind of slop.
The advantage, when it accrues, will accrue to the people who do not get distracted. Who do not subscribe to the dashboard. Who keep working on product-driven SEO and the foundations that have always connected content to people. There are early signs of this on the timelines I read. Practitioners openly questioning whether optimising against a non-deterministic surface makes sense at all, and asking whether their attention belongs back on classical search; which, at the end of the chain, is what feeds these systems anyway.
The mess was always the point. The architecture handles it. The industry just needs to stop pretending the mess is the problem.
This is amazing! What I felt and many people feel behind optimizing for “GEO” and the probabilistic obstacles by design in the way!
Insightful and cutting piece.