

The AI Visibility Mirage: You're Not Ranking, You're Gambling
On AI visibility metrics, the incentive crisis for creators, and why optimizing for stochastic token prediction is gambling, not strategy.

This is an English adaptation of my interview with Roberto Serra, originally published in Italian on roberto-serra.com. Roberto runs SEO Confidential, a series featuring conversations with international SEO professionals. I’m sharing my responses here for English-speaking readers.
Roberto: If a growing part of SEO work will be absorbed by AI, what skills will really be crucial to remain useful to clients and not be replaced by automation?
Pedro: I believe that artificial intelligence will absorb the operational aspects of SEO rather than the strategic ones. Automation will handle tasks such as tool usage, data analysis, and pattern identification. As a result, I think SEOs need to prioritize critical thinking and strategy, demonstrating their value through innovation and creative problem solving. Ultimately, SEO professionals need to evolve into growth-oriented decision makers who oversee operational execution.
Roberto: You say that publishing too much know-how ends up feeding models that then compete with content creators. Given that many systems ignore blocks and continue to collect data, what strategy can a professional adopt today to protect their value without losing online visibility?
Pedro: I believe that if you publish everything you know for free, you will likely end up with a weak competitive advantage, if any at all. Artificial intelligence was created to meet specific problem-solving needs, and most of us use it to get things started quickly. However, as the capabilities of artificial intelligence increase, so do its skills. The more training data it consumes, the more capable it becomes.
SEOs have historically been big advocates of open knowledge sharing. But in an industry driven by strategy and the need to stay ahead of the curve, this openness could lead to a race to the bottom, as AI absorbs your best insights.
Now it’s up to each professional to assess how much they’re willing to invest in publishing and how in-depth their content needs to be. The goal is to find a balance: reveal enough to showcase your expertise, but hold back enough to protect your competitive advantage.
Roberto: Cloudflare offers sites much more explicit control over the use of content by AI. Could this be the beginning of a real redefinition of the pact between creators and platforms, or does it remain a symbolic gesture until Google, OpenAI, Anthropic, and other Big Tech companies clarify how they intend to move forward?
Pedro: We urgently need a control mechanism to safeguard our interests. Every content producer, creator, artist, and researcher should have a say in how and by whom their content is used.
The open web should not be a free archive where anyone can simply take and reuse content without agreement or consent. We experienced a similar change in the early 2000s when search engines emerged, and we should have learned from that experience.
While the implementation of the robots.txt exclusion protocol was a step in the right direction, it’s really like an open glass door with a guest list written on a Post-it note: anyone can walk in without asking permission or being on the list.
Regardless of the gestures of goodwill or data controls offered by tech companies, we need a system that gives unilateral and undisputed control to creators. Otherwise, I fear that the incentive to produce content will vanish, leaving us with a significantly poorer web.
Roberto: Cloudflare attributed a recent global blackout to a single faulty query that crashed the bot protection system. Is this an isolated incident, or does it reveal a structural fragility in the infrastructure that supports a huge part of the web?
Pedro: I believe that any single point of failure in such critical infrastructure should be cause for great concern. We have become heavily dependent on web services for both our work and our daily lives. Almost all appliances, electronic devices, and smart gadgets connect to a CDN or AWS instance somewhere.
As a result, it is unacceptable for the entire ecosystem to come to a halt because of a single point of failure. Just as we have multiple routes and modes of travel to choose from, we need to create digital redundancies to ensure that the web continues to function even if a single service provider fails.
Roberto: Many tools promise to measure visibility in AI responses, but there are huge doubts about personalization, context, and the technical limitations of the models. If these factors are not considered, what kind of reality do those numbers really represent? Why do you think part of the SEO community seems so reluctant to really question the quality and reliability of the data these tools provide?
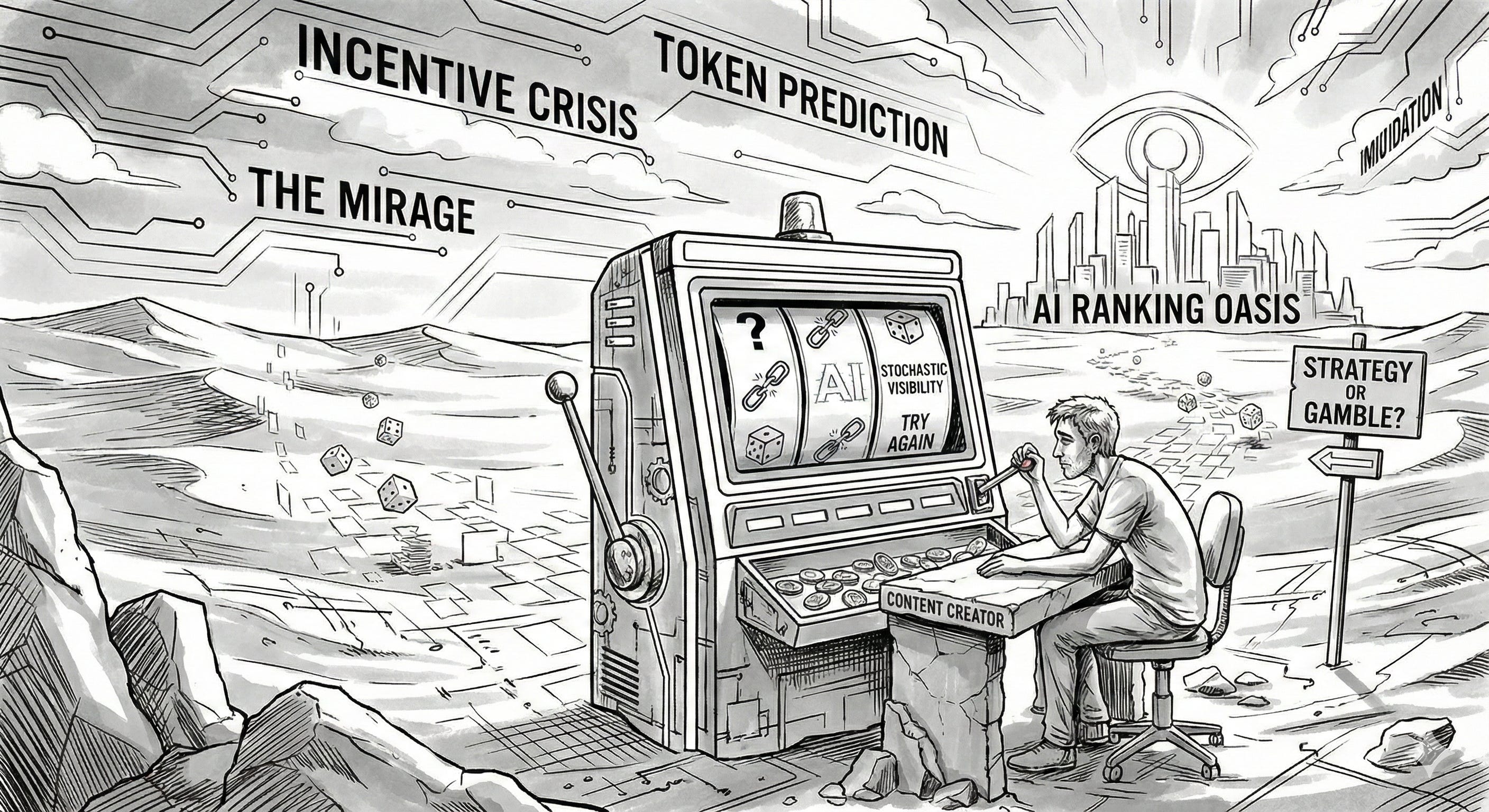
Pedro: They represent a statistical hallucination. When tools ignore the non-deterministic nature of LLMs, coupled with a lack of access to user context, the numbers they produce are essentially “garbage.”
We are dealing with stochastic black boxes, not deterministic indices. Therefore, these metrics do not represent a “ranking,” but rather a “lottery ticket.” A tool might tell you that you are visible in a response, but without understanding the temperature, seed, and specific context of the user, that data is just noise masquerading as insight.
As for the lack of reaction from SEOs, I believe it is because the alternative is to admit that we are currently flying blind. The industry is drowning in a sea of illusions; agencies and professionals are under enormous pressure to prove the ROI of “AI strategies.”
Questioning the data would mean admitting that the “directional” charts they show clients are largely based on assumptions. It’s easier to accept the “mirage” of AI’s exclusive visibility than to admit that there is currently no scientific way to measure it, especially when even the engineers who build these models are unable to fully explain the inference path.
Roberto: Many of GEO’s “novelties” are nothing more than SEO principles that should have always applied, such as brand, authority, and product quality. How, then, do you explain that part of the industry continues to chase superficial metrics and sell old practices as if they were revolutionary? And what risks do those who build their strategy on this narrative run?
Pedro: It is a classic case of “magical thinking” fueled by the frantic need to remain relevant. By assigning acronyms such as GEO or AEO to fundamental principles such as “clarity” and “structure,” the industry creates an artificial battle to sell new services.
This suggests that LLMs have developed a sophisticated and unique taste for quality that Google has somehow overlooked, when in reality optimization is still only about how machines acquire and understand data.
The risk is that people are building their strategy on “temperature and noise” rather than sustainable foundations. If you think you’ve uncovered a secret “AI-only” variable because a chatbot turned your brand into a phrase, you’re confusing a probabilistic roll of the dice with a strategy.
The danger is that when you optimize for stochastic token prediction rather than deterministic foundation (RAG), the results are random. You haven’t outsmarted an algorithm, you’ve just gotten lucky in the chain of inferences. That’s not a business model, it’s gambling.
Roberto: When it comes to tracking visibility in AI responses, many compare prompt personalization to traditional search result personalization. How accurate is this equivalence, and what role do the now-obvious limitations of keyword tracking and query group-based systems play in this context?
Pedro: This is a fundamental misunderstanding of the difference between an index and a generator. Comparing the two is technically incorrect. Traditional search is deterministic retrieval; AI responses are probabilistic predictions.
The only predictable part of an AI response is “grounding” (RAG), which relies on the exact same retrieval mechanisms (indexing, vector search) as traditional search. There is no magical “AI retrieval layer” separate from technical reality.
The limitations confirm that most “AI tracking” is useless. Since we cannot see or extract the context-based personalization of an LLM, and since we have no verifiable data on how users actually query these systems, any tool that claims to track this aspect is “reaching assumptions.”
If you are not indexable and analyzable according to standard search principles, you cannot be used for grounding. Therefore, “new” visibility is just old retrieval visibility with a pair of fake whiskers. Until we have data that is not just “junk” noise, we will treat stochastic parrots as oracles.
A note for readers unfamiliar with the term: “stochastic parrot” describes an AI that repeats what it has learned from data without really understanding it. The model analyzes huge amounts of text, identifies the most likely patterns, and combines them to create new sentences. The result sounds sensible, but there is no understanding behind it—only statistics.
Roberto: The study by Kaiser and Schulze shows that traffic from ChatGPT is almost invisible and converts very little, while Google continues to dominate the decision-making phase. How do you assess this clear gap between “understanding” and “buying” in user behavior?
Pedro: This gap is not surprising: it is the architecture of the technology. Search engines function as transit hubs: their value lies in redirecting you to a destination. LLMs function as destinations: their value lies in synthesizing the answer so that you don’t have to leave.
The study confirms exactly what technical reality dictates: when an AI successfully uses grounding (RAG) to respond to a query, it satisfies the intent in situ. The “low traffic” statistic is actually proof that the models are doing their job: extracting information and eliminating the need to click.
As for the conversion gap: users are not stupid. When money is at stake, we want deterministic certainty. We trust a navigable list of verified websites/suppliers (Google) rather than a probabilistic recommendation from a chatbot that may be unreliable. We use AI to summarise the manual, but we use research to buy the car.
Roberto: EBU–BBC studies show that AI assistants are wrong almost half the time and base many answers on absent or misleading sources. How do you assess the impact of this unreliability on the visibility and reputation of companies that depend on online search?
Pedro: This study confirms what technical realists have been warning about from day one: the race for “AI visibility” is actually a gamble.
I recently shared a study highlighting how hallucinations are a structural feature of the design, not a bug (here is the link to the paper).
These models are not designed for truth, but for plausibility. By definition, they prioritise fluency over accuracy. Therefore, when the BBC detects high error rates, we are not necessarily witnessing a malfunction, but the system functioning exactly as designed.
If these models hallucinate in 50% of cases, fighting to be included in their responses means that statistically you are just as likely to be part of a lie as you are to be part of a fact.
For a brand, this is not just an accuracy issue, but a serious brand safety crisis waiting to happen. We need to stop pretending that LLMs are knowledge bases; they are probabilistic sentence completers. When a model invents a source or attributes a false claim to a company, it is not “making a mistake” in the human sense of the word, but simply predicting the next plausible token based on its training weights.
For companies, this creates a dangerous paradox: the industry pushes them to optimize a platform that could confidently destroy their reputation in the next inference.
Until Grounding (RAG) mechanisms are rigorously applied and the hallucination rate drops from “coin flip” to “near zero,” building a strategy around AI visibility is not marketing, but is highly likely to turn into liability management. This reinforces why deterministic and reliable search remains the only safe environment for transactional and factual queries.
Roberto: Academic research talks about “brain rot” in models trained with poor content, triggering a cycle of degradation that is difficult to reverse. What kind of risks do you see for the entire information ecosystem if models continue to feed on data generated by other AIs?
Pedro: I see this dynamic turning into a self-fulfilling prophecy, or what researchers call Model Collapse. A “digital ouroboros” is being built—the snake that devours its own tail. Artificial intelligence models are probabilistic engines that operate by converging toward the mean; they attenuate exceptions to generate “average” and plausible content.
Innovation, however, arises from exceptions. If the ecosystem is flooded with synthetic and uniform content, and models begin to train on that material, the quality of information slips into a cycle of error and mediocrity.
This process runs faster because of the economic factor mentioned earlier: incentive. If content creators are not rewarded for novelty because their work is extracted without consent or attribution, they will simply stop publishing.
AI cannot invent: it can only remix.
If you remove the human incentive to produce the “new,” you cut off the fuel that feeds these models. The likely result will be poorer AI and a stagnant culture.
Thanks to Roberto Serra for the thoughtful questions. You can find the original Italian version on his site.